https://apps.prometheus.org.ua/learning/course/course-v1:LinuxFoundation+INTRO101+2023_T1/home
prometheus.org.ua
Основи Kubernetes
Розділ 1 та 2 — 29 березня
Розділ 3 та 4 — 5 квітня
Розділ 5 та 6 — 12 квітня
Розділ 7 та 8 — 19 квітня
Розділ 9 та 10 — 26 квітня
Розділ 11 та 12 — 3 травня
Розділ 13 та 14 — 10 травня
Розділ 15 — 17 травня
Вітаємо вас на курсі «Основи Kubernetes», який створений The Linux Foundation – амбасадорами відкритого коду та головними фахівцями у цій провідній операційній системі – та перекладений українською мовою платформою Prometheus!
На цьому курсі ми обговоримо базові концепції Kubernetes, поговоримо про архітектуру системи, проблеми, які вона вирішує, та модель, яку вона використовує для роботи з розгортанням та масштабуванням контейнерів. Курс пропонує вступ до Kubernetes та містить технічні інструкції щодо розгортання автономних та багаторівневих застосунків. Ви дізнаєтесь про ConfigMaps та Secrets, а також про те, як використовувати Ingress.
Впродовж 9 тижнів у середу ми будемо відкривати по два нових розділи курсу,…
…
Розділ 1.
Від монолітної структури до мікросервісів.
Огляд розділу.
Більшість нових компаній сьогодні виконують свої бізнес-процеси у хмарах. Нові стартапи та підприємства, які вчасно змогли зрозуміти напрямок розвитку технологій, розробили власні застосунки для хмарних платформ.
Не всім компаніям так пощастило. Деякі з них забезпечили свій успіх багато років тому, ще за часів старих технологій – монолітних програм, у яких усі компоненти було тісно пов’язані між собою і які практично неможливо роз’єднати, а їх розміщення і управління буде потребувати дуже дорогого обладнання.
Припустимо, ви працюєте в організації, яка називає свій основний бізнес-застосунок «чорною скринькою». І ніхто не знає, що відбувається всередині. Більшість логіки процесів не було ніколи задокументовано, тому ніхто не розуміє, що відбувається з моменту надходження запиту до застосунку до моменту отримання відповіді. Вам доручено перетворити цей бізнес-застосунок на набір застосунків, які будуть готові до роботи в хмарі. На вас чекає довга та непроста робота.
Навчальні цілі.
Після опанування розділу ви зможете:
- Пояснювати, що таке моноліт.
- Обговорювати проблеми моноліта в хмарі.
- Пояснити концепцію мікросервісів.
- Розказати про переваги мікросервісів в хмарі.
- Описати шлях трансформації від моноліту до мікросервісів.
После овладения разделом вы сможете:
- Объяснять, что такое монолит.
- Обсуждать проблемы монолита в облаке.
- Объяснить концепцию микросервисов.
- Рассказать о преимуществах микросервисов в облаке.
- Описать путь трансформации от монолита в микросервисы.
Монолит.
Хотя большинство компаний считают, что облако станет новым домом для предыдущих (legacy) приложений, не все они подходят для облака, по крайней мере, пока.
Перенос приложения к облаку должен быть таким же простым, как прогулка по пляжу и сбор камешков в ведерко, чтобы легко переносить их туда, куда нужно. С другой стороны, глыбу весом 1000 тонн вообще перенести нелегко. Эта глыба и является монолитным приложением – оседлые слои из функций, чрезмерной логики, переведенные на тысячи строк кода, написанные единственным, не очень современным языком программирования, основанным на устаревших шаблонах и принципах архитектуры программного обеспечения.
Со временем новые усовершенствования и функции добавляют сложности в код, что делает разработку более проблемной – время загрузки, компиляции и сборки увеличивается с каждым новым обновлением. Однако администрирование несколько упрощается, поскольку приложение работает на одном сервере, в идеале – на виртуальной машине или мэйнфрейме.
Монолит достаточно требователен к оборудованию. Как большая и единственная программа, которая продолжает постоянно расти, его необходимо запускать на одной и той же системе, которая будет удовлетворять потребности в вычислительной способности, памяти, хранилище и сетевых требованиях. Аппаратное обеспечение такой мощности не только непростое и очень дорогое, но и сложное в приобретении.
Поскольку все монолитное приложение работает как единый процесс, масштабирование отдельных функций монолита почти невозможно. Он внутренне поддерживает закодированное количество соединений и операций. Однако, масштабирование всей программы можно достичь путем ручного развертывания нового экземпляра монолита на другом сервере, как правило, с помощью программно-аппаратной балансировки нагрузки – еще одно дорогостоящее решение.
При обновлении, исправлении или переносе монолитного приложения отключения неизбежны и временные окна должны быть хорошо спланированы заранее, поскольку перебои в обслуживании могут повлиять на клиентов. Хотя существуют посторонние решения для минимизации времени обслуживания клиентов путем настройки монолитных приложений в высоко доступной «активной/пассивной» конфигурации, они создают новые вызовы для системных инженеров, чтобы поддерживать все системы на одном уровне патчей, а также могут вызвать новые возможные расходы на лицензирование .
Современный микросервис.
Камни, в отличие от 1000-тонной глыбы, гораздо легче обрабатывать. Они вырезаются из монолита, отделяются друг от друга, становятся распределенными компонентами, каждый из которых описывается набором конкретных характеристик. Вместе все эти камни составляют вес целой глыбы. Эти камешки – это слабо связанные микросервисы, каждый из которых выполняет определенную бизнес-функцию. Все функции сгруппированы вместе и формируют общую функциональность оригинального монолитного приложения. Камни легко выбирать и группировать вместе по цвету, размеру, форме, а их перенос при необходимости требует минимум усилий. Попробуйте без особого труда переместить 1000-тонную глыбу.
Микросервисы можно развернуть индивидуально на отдельных серверах с меньшим количеством ресурсов – только необходимыми для каждого сервиса и самого хоста, что помогает снизить затраты на вычислительные ресурсы.
Архитектура на основе микросервисов соответствует принципам архитектуры, ориентированной на события, и сервис-ориентированной архитектуре (SOA), где сложные приложения состоят из небольших независимых процессов, взаимодействующих между собой посредством интерфейсов программирования приложений (API) через сеть. API предоставляет доступ к другим внутренним сервисам той же программы или к внешним сервисам и приложениям.
Каждый микросервис разрабатывается и написан современным языком программирования, который выбран так, чтобы лучше соответствовать типу сервиса и его бизнес-функциям. Это обеспечивает большую гибкость при выборе микросервисов к конкретному аппаратному обеспечению, что позволяет разворачивать их на обычном недорогом оборудовании.
Хотя распределенная природа микросервисов добавляет сложности в архитектуру, одним из самых больших преимуществ микросервисов является масштабируемость. Поскольку все приложение становится модульным, каждый микросервис можно масштабировать отдельно, либо вручную, либо автоматизирован с помощью автоматического масштабирования на основе спроса.
Еще одним преимуществом микро сервисной архитектуры является бесперебойное обновление и исправление ошибок. Обновления практически не приводят к простоям и перебоям в предоставлении услуг клиентам, поскольку обновления производятся беспрепятственно – по одному сервису за раз вместо того, чтобы перекомпилировать, перестраивать и перезапускать все монолитное приложение. Как результат, бизнес может разрабатывать и выпускать новые функции и обновления гораздо быстрее, по гибкому подходу, с отдельными командами, фокусирующимися на отдельных функциях, что делает их более производительными и экономически эффективными.
Рефакторинг.
Новые, более современные компании обладают знаниями и технологиями для создания облачных приложений для работы их бизнесов.
К сожалению, это не касается стабильных компаний, работающих на устаревших монолитных приложениях. Некоторые пытались запустить монолиты как микросервисы, и, как и ожидалось, это не очень хорошо сработало. Извлеченные уроки заключались в том, что многопроцессорное приложение монолитного размера не может работать как микросервис, и что нужно искать другие варианты. Следующим естественным шагом в переходе от монолита к микросервисам был рефакторинг. Однако перенос программы десятилетней давности в облако через рефакторинг создает серьезные вызовы, и компания сталкивается с дилеммой подхода к рефакторингу: «Большой взрыв» или инкрементальный рефакторинг.
Так называемый подход «Большого взрыва» направляет все усилия по переработке (рефакторингу) монолита, откладывая разработку и внедрение любых новых функций, что существенно задерживает прогресс и, возможно, даже разрушает основу бизнеса – монолит.
Подход инкрементного рефакторинга гарантирует, что новые функции разрабатываются и внедряются как современные микросервисы, которые могут взаимодействовать с монолитом через API, не внося изменений в код монолита. В то же время функции постепенно переносятся из медлительно исчезающего монолита, а его функциональность модернизируется в микросервисы. Такой инкрементальный подход предлагает постепенный переход от устаревшего монолита к современной архитектуре микросервисов и позволяет поэтапно переносить приложения к облаку.
После того как компания выбирает путь рефакторинга, в процессе возникают другие вопросы. Какие бизнес-компоненты отделить от монолита, чтобы сделать распределенными микросервисами, как отделить базы данных от приложения, чтобы разделить сложность данных от логики приложения, и как протестировать новые микросервисы и их зависимости — это лишь некоторые решения, с которыми компания сталкивается во время рефакторинг.
Этап рефакторинга медленно превращает монолит в облачное приложение, полностью использующее все преимущества облачных функций благодаря кодированию на новых языках программирования и применению современных архитектурных паттернов. Благодаря рефакторингу устаревшее монолитное приложение получает второй шанс на жизнь – существовать как модульная система, адаптированная для полного интегрирования со скоростными инструментами и сервисами облачной автоматизации.
Вызовы.
Путь преобразования (рефакторинга) от монолита в микросервисы непрост и связан с определенными проблемами. Не все монолиты являются идеальными кандидатами для рефакторинга, а некоторые могут даже не пережить такой этап модернизации. Решая, является ли монолит возможным кандидатом для рефакторинга, важно учитывать многие факторы.
Когда вы рассматриваете устаревшую систему, базирующуюся на базе мейнфреймов, написанных на старых языках программирования – Cobol или Assembler, возможно будет экономически целесообразнее просто перестроить их с нуля как облачное приложение. Плохо спроектированное устаревшее приложение нужно перепроектировать и перестроить с нуля с использованием современных архитектурных паттернов для микросервисов и контейнеров. Приложения, тесно связанные с хранилищами данных, также являются плохими кандидатами для рефакторинга.
После того, как монолит успешно прошел этап рефакторинга, следующим вызовом является разработка механизмов или нахождение соответствующих инструментов для обеспечения жизнеспособности всех обособленных модулей, чтобы гарантировать устойчивость приложения в целом.
Выбор среды выполнения (рантаймов) может являться еще одной проблемой. Если на одном физическом или виртуальном сервере развертывать много модулей, существует риск, что различные библиотеки и среды выполнения будут конфликтовать между собой, что приведет к ошибкам и сбоям. Это заставляет развертывать отдельные модули на отдельных серверах, чтобы отделить их зависимости, а это не очень экономичный способ и не обеспечивает реального распределения библиотек и сред выполнения, поскольку каждый сервер имеет базовую операционную систему со своими библиотеками, что иногда использует больше ресурсов, чем сам модуль приложение.
Со временем появилось решение, позволяющее решить проблемы с рефакторингом. Таким решением стали контейнеры программных приложений, обеспечивающие изолированные легкие среды исполнения для модулей. Контейнеры обещают постоянную программную среду для разработчиков, тестировщиков и всех, кто работает с приложением, начиная с разработки и заканчивая производительной средой. Широкая поддержка контейнеров гарантировала перенос приложений с физических серверов в виртуальные машины, но уже с возможностью развертывания многих приложений на одном сервере, причем каждый из них работает в своей среде выполнения, изолированной от других, что позволяет избежать конфликтов, ошибок и отказов. Другие преимущества контейнеров – высокая используемость сервера, масштабируемость отдельных модулей, гибкость, совместимость и легкая интеграция с инструментами автоматизации.
Истории успеха.
Хотя это и сложный процесс, переход от монолитов к микросервисам полезен, особенно после того, как бизнес начинает расти и становиться успешным. Это обеспечивается рефакторинговой системой приложений. Ниже мы приведем лишь несколько историй успеха компаний, принявших вызов модернизации своих монолитных бизнес-приложений. Подробный список историй успеха доступен на вебсайте Kubernetes: Интересные кейсы пользователей Kubernetes.
AppDirect – поставщик комплексных коммерческих платформ, начавший деятельность со сложного монолитного приложения и, благодаря рефакторингу, смог сохранить ограниченную функциональность монолита, получавшего очень мало комитов, однако все новые функции реализованы в виде контейнерных микросервисов.
box – поставщик решений для облачного хранилища, начал со сложной монолитной архитектуры и благодаря рефакторингу смог разложить ее на микросервисы.
Crowdfire – поставщик решений для управления контентом, успешно разбивший свой начальный монолит на микросервисы.
GolfNow – поставщик технологий и услуг, решил разбить свой монолит на контейнерные микросервисы.
Pinterest – поставщик услуг социальных сетей, начавший процесс рефакторинга с миграции своего монолитного API.
Проверка знаний 1.1
Как мы называем приложение, занимающее много места, написанное устаревшим языком программирования, с тесно связанными функциями, работающими на выделенном, большом и дорогом сервере? (Это Монолит. Монолит.)
Камень
Монолит.
1000-тонная глыба
БигфутПроверка знаний 1.2.
Какие функции появляются в микро сервисах после рефакторинга? Ответ: Это Модульность и Разделение (изоляция).
Выберите все правильные ответы.
Модульность (верно)
Фиксированное масштабирование
Камни
Разделение (изоляция) (верно)Проверка знаний 1.3.
Устаревшее приложение для мейнфреймов, написанное на языке Cobol и тесно связанное с хранилищами данных, является лучшим кандидатом для модернизации с помощью рефакторинга. Это утверждение истинно или нет?
Истинно ли Ложно?
Ответ: Ложное.
Учебные цели (Итог)
Теперь вы можете:
Объяснить, что такое монолит.
Обсуждать проблемы монолита в облаке.
Объяснить концепцию микросервисов.
Обсуждать преимущества микросервисов в облаке.
Описать путь преобразования от монолита в микросервисы.
Розділ 2. Оркестрування контейнерів.
Раздел 2. Оркестрирование контейнеров.
Обзор раздела.
Образы контейнеров позволяют нам ограничить код программы, время выполнения и все зависимости в заранее определенном формате. Контейнерные среды выполнения, такие как runC, containerd или cri-o, могут использовать предварительно упакованные образы в качестве источника для создания и запуска одного или нескольких контейнеров. Эти среды выполнения способны запускать контейнеры на одном хосте, хотя на практике хотелось бы иметь отказоустойчивое и масштабируемое решение, достигаемое созданием единого контроллера/управления, коллекции нескольких хостов, соединенных вместе. Этот контроллер/управленческий блок обычно называют оркестром контейнеров.
В этом разделе мы разберемся, почему следует использовать оркестрирование контейнеров, рассмотрим различные способы оркестрирования и где их разворачивать.
Учебные цели.
После овладения разделом вы сможете:
Определить концепцию оркестрирования контейнеров.
Объяснить преимущества использования оркестрирования контейнеров.
Обсудить разные варианты оркестрирования контейнеров.
Обсудить разные варианты развертывания оркестраторов контейнеров.
Что такое контейнеры?
Прежде чем перейти к оркестрированию контейнеров, сначала рассмотрим, что такое контейнеры.
Контейнеры – это ориентированный на приложения способ использования и обеспечения работы высокопроизводительных и масштабируемых программных продуктов на любой выбранной инфраструктуре. Контейнеры наиболее подходят для распределенных микросервисов, предоставляя портативные и изолированные виртуальные среды для запуска приложений без вмешательства.
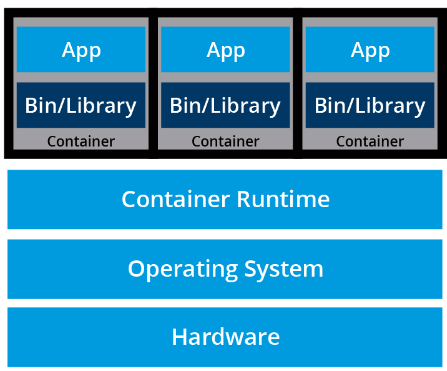
Развертывание контейнеров.
Микросервисы – это легкие приложения, написанные на разных языках программирования с конкретными зависимостями, библиотеками и требованиями к среде. Для обеспечения успешного запуска приложение упаковывается с зависимостями.
Контейнеры изолируют микросервисы и их зависимости, но не запускают их напрямую. Контейнеры запускают образы контейнеров.
Образ контейнера – это комплексный пакет, содержащий приложение вместе с его средой исполнения, библиотеками и зависимостями. Он является источником развертывающегося контейнера, предоставляя изолированную исполнительную среду для приложения. Контейнеры могут быть развернуты из конкретного образа на многих платформах, таких как рабочие станции, виртуальные машины, публичные облачные сервисы и т.д.
Что такое оркестрирование контейнеров?
В средах разработки (Dev) можно запускать контейнеры на одном хосте для разработки и тестирования приложений. Однако при миграции к средам качества (QA) и непосредственному запуску (Prod) это уже не будет приемлемым вариантом, поскольку приложения и сервисы должны соответствовать определенным требованиям.
Отказоустойчивость.
Масштабируемость при необходимости.
Оптимальное использование ресурсов.
Автоматическое обнаружение и взаимодействие между контейнерами.
Доступность извне.
Непрерывные обновления/откатки без каких-либо сбоев.
Оркестраторы контейнеров.
Компании постоянно контейнеризируют свои приложения и переносят их в облака, растет спрос на решения для оркестрирования контейнеров. Хотя таких решений уже достаточно много, некоторые из них просто переосмысление уже установленных инструментов для оркестрирования контейнеров, обогащенных функциями и иногда с определенными ограничениями в гибкости.
Хотя список ниже не является исчерпывающим, он предоставляет несколько различных инструментов и сервисов для оркестрирования контейнеров, которые доступны сегодня.
Смотри список №1.
- Amazon Elastic Container Service (ECS) – это хостинговый сервис, предоставляемый Amazon Web Services (AWS) для запуска контейнеров в масштабе на его инфраструктуре.
- Azure Container Instance (ACI) – это базовый сервис контейнерной оркестрации, предоставляемый Microsoft Azure .
- Azure Service Fabric — это открытый контейнерный оркестратор, предоставляемый Microsoft Azure .
- Kubernetes – это открытый оркестрационный инструмент, который был первоначально создан Google, сегодня является частью проекта Cloud Native Computing Foundation (CNCF).
- Marathon – это фреймворк для запуска контейнеров с масштабированием на Apache Mesos and DC/OS .
- Nomad — это оркестратор контейнеров и рабочих нагрузок, предоставляемый HashiCorp .
- Docker Swarm – это оркестратор контейнеров, предоставляемый Docker, Inc. Является частью Docker Engine.
Зачем использовать оркестрирование контейнеров?
Хотя мы можем вручную управлять несколькими контейнерами или писать скрипты для управления жизненным циклом десятков контейнеров, оркестраторы делают все проще для пользователей, особенно когда речь идет об управлении сотнями и тысячами контейнеров, работающих на глобальной инфраструктуре.
Большинство оркестраторов контейнеров могут:
Группировать хосты вместе, создавая кластер.
Раскладывать контейнеры на хосты в кластере в соответствии с имеющимися ресурсами
Разрешать контейнерам в кластере общаться между собой, независимо от хоста, на котором они развернуты в кластере.
Связывать контейнеры и ресурсы хранилища.
Группировать наборы подобных контейнеров и связывать их с механизмами балансировки нагрузки, чтобы упростить доступ к контейнеризированным приложениям путем создания интерфейса, уровня абстракции между контейнерами и клиентом
Управление и оптимизация использования ресурсов.
Разрешать реализовать политику обеспечения безопасности доступа к приложениям, работающим в контейнерах.
Со всеми этими настраиваемыми, но гибкими возможностями оркестраторы контейнеров являются очевидным выбором, когда речь идет об управлении контейнеризированными приложениями в масштабе. В этом курсе мы исследуем Kubernetes, один из самых популярных инструментов оркестрирования контейнеров среди доступных в настоящее время.
Где лучше разворачивать оркестрирование контейнеров?
Большинство оркестраторов контейнеров могут быть развернуты на инфраструктуре по выбору – на голом железе (bare metal), виртуальных машинах, локальных серверах, на публичных и гибридных облаках. Например, Kubernetes может быть развернут на рабочей станции с или без изоляционного слоя, такого как локальный гипервизор или контейнерная среда запуска, в дата-центре компании, в облаке AWS Elastic Compute Cloud (EC2), Google Compute Engine (GCE) VMs, DigitalOcean Droplets, OpenStack и т.д.
Существуют готовые решения, которые позволяют устанавливать кластеры Kubernetes с помощью всего нескольких команд на верхнем уровне инфраструктуры как-сервиса, таких как GCE, AWS EC2, IBM Cloud, Rancher, VMware Tanzu и многооблачных решениях через IBM Cloud
Не стоит забывать и об управляемых оркестраторах контейнеров как сервис, в частности, управляемых Kubernetes как сервис, предлагаемых и хостящихся ведущими облачными провайдерами, такими как Amazon Elastic Services (Amazon EKS), Azure Services (AKS), DigitalOcean Kubernetes, Google Kubernetes (GKE), IBM Cloud Kubernetes Service, Oracle Container Engine for Kubernetes или VMware Tanzu Kubernetes Grid.
Проверка знаний 2.1.
Какие преимущества имеет оркестрирование контейнеров?
Ответ: Отказоустойчивость. Также Оптимальное использование ресурсов. Также Масштабирование приложений.
Отказоустойчивость,
Оптимальное использование ресурсов,
Масштабирование приложений.
Все указанные варианты (верно).Проверка знаний 2.2.
Что могут делать оркестраторы контейнеров? Выберите все правильные ответы.
Ответ:
Разлагать контейнеры на разных узлах.
и
Помочь соединить контейнеры, развернутые на разных хостах в одном кластере.
Проверка знаний 2.3.
Что из этого приведенного относится к оркестраторам контейнеров? Выберите все правильные ответы.
Ответ:
Docker Swarm
и
Kubernetes
Учебные цели (Итог).
Теперь вы можете:
Определить концепцию оркестрирования контейнеров.
Объяснить преимущества использования оркестрирования контейнеров.
Обсудить разные варианты оркестрирования контейнеров.
Обсудить разные варианты развертывания оркестрирования контейнеров.
Глава 3. Kubernetes. / Введение.
Посмотреть раздачу.
В этом разделе мы поговорим о Kubernetes, его возможностях и причинах использования именно его. Мы рассмотрим эволюцию Kubernetes от Borg, менеджера по распределению рабочих нагрузок от Google.
Мы также узнаем о Cloud Native Computing Foundation (CNCF), которая сейчас занимается и размещает проект Kubernetes, а также другие популярные облачные проекты, такие как Prometheus, Fluentd, cri-o, containerd, Helm, Envoy и Contour, и это только для примера .
Учебные цели.
Овладев этим разделом, вы можете:
- Определять, что такое Kubernetes.
- Объяснять причины использования Kubernetes.
- Обсуждать основные характеристики Kubernetes.
- Говорить об эволюции Kubernetes от Borg.
- Объяснять роль Cloud Native Computing Foundation в Kubernetes.
Что такое Kubernetes?
Как указано на вебсайте Kubernetes,
«Kubernetes – это система с открытым кодом для автоматизации развертывания, масштабирования и управления контейнерными приложениями».
Слово Kubernetes происходит от греческого κυβερνήτης, что означает вождь или штурман корабля. Если следовать этой аналогии, мы можем представить Kubernetes в качестве штурмана на корабле с контейнерами.

Kubernetes также называют k8s (произносится как «кейтс»), поскольку в слове Kubernetes между «к» и «с» находится 8 символов.
Kubernetes в значительной степени вдохновлен системой Google Borg, которая более 10 лет является оркестром контейнеров и рабочих нагрузок для глобальных компаний. Kubernetes – это объект с открытым кодом, написанный на языке Go и лицензированный по лицензии Apache License, Version 2.0.
Kubernetes был создан Google, и с релизом v1.0 в июле 2015 года компания Google передала его в собственность Cloud Native Computing Foundation (CNCF), одному из крупнейших подфондов The Linux Foundation.
Новые версии Kubernetes выходят с циклом в 4 месяца. Текущая стабильная версия – 1.26 (по состоянию на декабрь 2022 года).
От Borg до Kubernetes.
Согласно аннотации статьи Google о Borg, опубликованной в 2015 году,
«Система Borg от Google – это кластерный менеджер, выполняющий сотни тысяч задач из многих тысяч различных приложений в нескольких кластерах, каждый из которых насчитывает до десятка тысяч машин».
Более 10 лет система Borg была тайной разработкой Google, запускавшей контейнерные нагрузки по всему миру. Сервисы Google, которые мы используем, например Gmail, Drive, Maps, Docs и другие, обслуживаются с помощью Borg.
Среди первых авторов Kubernetes были сотрудники Google, использовавшие Borg и разрабатывавшие его в прошлом. Они вложили свои знания и опыт в разработку Kubernetes. Несколько особенностей/объектов Kubernetes можно отследить до Borg или к тому, чему эта система нас научила:
- серверы API;
- поды (pods);
- IP-per-pod
- сервисы;
- метки (labels).
Все эти особенности мы рассмотрим в рамках этого курса и даже больше.
Особенности Kubernetes.
Kubernetes предлагает множество возможностей для оркестрирования контейнеров. Перечислим лишь некоторые из них (эти возможности полностью поддерживаются Kubernetes):
- Автоматическая упаковка
Kubernetes автоматически планирует контейнеры на основе потребностей и ограничений ресурсов для максимизации их использования без снижения доступности. - Разработанный для расширения
Кластер Kubernetes можно расширять новыми пользовательскими функциями без изменения исходного кода. - Самообновление
Kubernetes автоматически заменяет и перезапускает контейнеры из вышедших из строя нод. Он завершает работу, а затем перезапускает контейнеры, не реагирующие на проверки состояния, на основе имеющихся правил/политики. Он также следит за тем, чтобы на неактивные контейнеры не перенаправлялся трафик. - Горизонтальное масштабирование
При использовании Kubernetes приложения можно масштабировать вручную или автоматически на основе использования процессора или пользовательских метрик. - Создание сервисов и балансировка нагрузки
Контейнеры получают IP-адреса от Kubernetes, а он назначает единственное DNS для набора контейнеров, чтобы помочь в балансировке нагрузки через запросы между контейнерами набора.
Дополнительные возможности Kubernetes (также полностью поддерживаются):
- Автоматизированные развертывания и откаты в прежнее состояние
Kubernetes плавно разворачивает и откатывает в прежнее состояние обновления программ и изменения конфигурации, постоянно отслеживая состояние программы, чтобы предотвратить любые сбои в работе. - Secret и управление конфигурациями
Kubernetes управляет конфиденциальной информацией и деталями конфигурации для приложения отдельно от образа контейнера, чтобы избежать копирования соответствующего образа. Secrets содержат конфиденциальную информацию, которая передается приложению без раскрытия чувствительного содержимого стека конфигурации, как на GitHub. - Оркестрирование хранилища
Kubernetes автоматически монтирует программно-определенные хранилища (SDS) в контейнеры из локального хранилища, внешние облачные провайдеры, распределенные хранилища или сетевые системы хранения. - Пакетное исполнение
Kubernetes поддерживает пакетное исполнение, длительные задания и заменяет неисправные контейнеры. - Поддержка двойного стека IPv4/IPv6
Kubernetes поддерживает как адреса по протоколу IPv4, так и по протоколу IPv6.
Многие дополнительные функции и возможности сейчас на стадии альфа или бета-тестирования. Они предоставят еще больше ценных функций для развертывания Kubernetes, как только превратятся в стабильные. К примеру, поддержка контроля доступа на основе ролей (RBAC) стала стабильной только начиная с версии Kubernetes 1.8.
Зачем использовать Kubernetes?
Еще одной из сильных сторон Kubernetes является портативность. Его можно разворачивать во многих средах, таких как локальные или удаленные виртуальные машины, платформы без операционных систем или в публичных/частных/гибридных/мультиоблачных средах.
Расширяемость Kubernetes позволяет поддерживать и поддерживаться многими открытыми посторонними инструментами, улучшающими возможности Kubernetes и предоставляющими пользователям многофункциональный опыт. Его архитектура является модульной и может дополняться. Она не только организует модульные, обособленные приложения микросервисного типа, но и соответствует паттернам обособленных микросервисов. Функциональность Kubernetes можно расширить, написав свои ресурсы, операторы, кастомные API, правила планирования или плагины.
Для успешного проекта с открытым кодом сообщество так же важно, как и отличный код. Kubernetes поддерживается активным сообществом по всему миру. В проекте принимают участие более 3200 участников, которые за время существования проекта сделали более 111000 коммитов. В разных городах и странах существуют группы для встреч, регулярно собираемых для обсуждения Kubernetes и его экосистемы. Сообщество делится на группы по интересам (Special Interest Groups, SIG), группы, специализирующиеся на отдельных темах, таких как масштабирование, платформы без операционной системы, сетевые технологии, хранилища и т.д. Мы узнаем больше о них в нашем последнем разделе Сообщество Kubernetes .
Пользователи Kubernetes.
Менее чем за десять лет с момента появления Kubernetes стал платформой, которую выбирают для управления своими рабочими нагрузками многие компании разного размера. Это решение для управления рабочими нагрузками в банковской сфере, образовании, финансах и инвестициях, игровом бизнесе, информационных технологиях, медиа и стриминге, онлайн-продажах, каршеринге, телекоммуникациях, ядерных исследованиях и многих других отраслях. На сайте Kubernetes можно найти многочисленные примеры и истории успеха пользователей:
- BlaBlaCar
- BlackRock
- Booking.com
- Box
- CapitalOne
- Haufe Group
- Huawei
- IBM
- ING
- Nokia
- Pearson
- Wikimedia
- Та багато інших.
Cloud Native Computing Foundation — Фонд облачных вычислений (CNCF).
Cloud Native Computing Foundation (CNCF) – один из крупнейших подпроектов The Linux Foundation . Цель CNCF – ускорить внедрение контейнеров, микросервисов и облачных приложений.

CNCF поддерживает множество проектов, и в будущем к ним прибавится еще больше. CNCF обеспечивает ресурсами каждый из проектов, но вместе с тем каждый проект продолжает функционировать независимо в рамках своей предыдущей структуры управления и со своими разработчиками и службой поддержки. Проект в рамках CNCF классифицируется по уровням зрелости: «Песочница» (Sandbox), «Инкубация» (Incubating) и «Выпуск» (Graduated). К моменту подготовки этого раздела более 10 проектов достигли статуса «выпускников», еще больше находятся на стадии «инкубации» и в «песочнице».
Среди популярных проектов-«выпускников»:
- Kubernetes – оркестратор контейнеров
- etcd — распределенное хранилище ключей-значений (key-value)
- CoreDNS — DNS-сервер
- containerd — среда выполнения контейнеров
- Envoy – облачное прокси
- Fluentd – унификация логов
- Harbor — реестр
- Helm – менеджер пакетов для Kubernetes
- Linkerd – сетка служб (service mesh) для Kubernetes
- Open Policy Agent – подсистема обработки политик (police engine)
- Prometheus – система мониторинга и база данных последовательной работы.
- Rook – облачный оркестратор хранилища для Kubernetes
Ключевые проекты на стадии инкубации:
- argo – обработчик рабочего процесса для Kubernetes
- Buildpacks.io – создает образы приложений
- CRI-O – среда выполнения контейнеров
- Contour — контролер ingress для Kubernetes
- gRPC — дистанционный вызов процедур (RPC)
- CNI – для сетевой работы с контейнерами Linux
- flux — непрерывная доставка для Kubernetes
- Knative – бессерверные контейнеры для Kubernetes
- KubeVirt – менеджер виртуальных машин на основе Kubernetes
- Notary — обеспечение безопасности данных
- И многие другие .
У «песочницы» CNCF есть много динамических проектов, ориентированных на метрики, мониторинг, уникальность, написание кода, бессерверность, безнодовие, которые вот-вот перейдут к «инкубатору» и, возможно, со временем к «выпуску». Пока многие активные проекты готовятся к запуску, другие архивируются, как только становятся менее активными и больше не пользуются спросом. Первыми заархивированными проектами являются среда выполнения контейнеров rkt , распределенная система OpenTracing и Brigade , инструмент автоматизации с управлением событий.
Проекты, находящиеся под CNCF, охватывают все этапы жизненного цикла облачного приложения – от выполнения в среде выполнения контейнеров до мониторинга и ведения логов. Это очень важно для целей, которыми управляется CNCF.
CNCF через Kubernetes.
Для Kubernetes Cloud Native Computing Foundation обеспечивает:
- Нейтральное место для торговой марки Kubernetes и правильное использование.
- Лицензионное сканирование ядра и кода.
- Юридические консультации по патентам и авторским правам.
- Создание и поддержка открытых учебных программ , тренингов и сертификация для облачных партнеров Kubernetes (KCNA), администраторов (CKA), разработчиков приложений (CKAD) и специалистов по безопасности (CKS).
- Рабочая группа по соответствию стандартам программного обеспечения.
- Активное продвижение Kubernetes.
- Поддержку специальных мер.
- Спонсорство конференций и встреч.
Проверка знаний 3.1.
Под какой лицензией работает Kubernetes?
Ответ: Apache License, Version 2.0
Проверка знаний 3.2.
На каком языке программирования написан Kubernetes?
Ответ: Go. Язык Go.
Проверка знаний 3.3.
Что из приведенного относится к возможностям Kubernetes? Выберите все верные ответы:
Ответ:
Самовосстановление .
также
Secrets и управление конфигурациями .
также
Горизонтальное масштабирование .
Учебные цели (Итоги).
Теперь вы можете:
- Определять, что такое Kubernetes.
- Объяснять причины использования Kubernetes.
- Обсуждать особенности Kubernetes.
- Говорить об эволюции Kubernetes от Borg.
- Объяснять роль Cloud Native Computing Foundation.
Раздел 3.
Обзор раздела.
В этом разделе мы рассмотрим архитектуру Kubernetes , компоненты ноды панели управления , роль рабочих нод , управление состоянием кластера с помощью etcd и требования к настройке сети. Мы также узнаем о сетевом интерфейсе контейнера сети (Container Network Interface, CNI) как сетевой спецификации Kubernetes.
Учебные цели.
Освоив этот раздел вы:
- Будете обсуждать архитектуру Kubernetes.
- Объясните различные компоненты панели управления и рабочих нод.
- Обсуждать управление состоянием кластера с помощью etcd.
- Рассмотрите требования Kubernetes к настройке сети.
Раздел 4.
Архитектура Kubernetes.
На самом высоком уровне Kubernetes – это кластер вычислительных систем, которые делятся на разные роли:
- Одна или более нод панели управления (control plane) .
- Одна или более рабочих нод (необязательно, но рекомендуется).
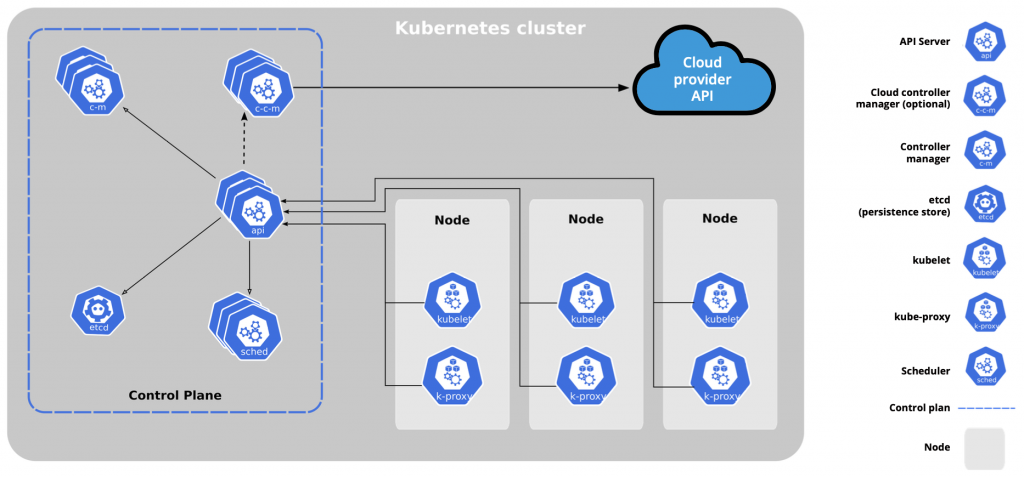
Компоненты архитектуры Kubernetes .
Нода панели управления (Control Plane Node): Обзор.
Нода панели управления (control plane node) обеспечивает рабочую среду для агентов панели управления (control plane agents), ответственных за управление состоянием кластера Kubernetes. Это мозговой центр всех операций внутри кластера. Компоненты панели управления – это агенты с очень четкими ролями в управлении кластером. Для того, чтобы общаться с кластером Kubernetes, пользователи посылают запросы в панель управления с помощью интерфейса командной строки (Command Line Interface, CLI), панели веб-интерфейса пользователя (Web UI) или интерфейса программирования приложений (API).
Важно поддерживать панель управления в рабочем состоянии любой ценой. Потеря панели управления может привести к простою, что приведет к перебоям в обслуживании клиентов и, возможно, приведет к потере бизнеса. Для обеспечения отказоустойчивости панели управления к кластеру можно добавить реплики нод панели управления, сконфигурированные в режиме высокой доступности (HA). Хотя только одна из нод панели управления предназначена для активного управления кластером, компоненты панели управления остаются синхронизированными на всех репликах нод панели управления. Такой тип конфигурации добавляет отказоустойчивость панели управления кластером, если активная нода панели управления откажет.
Для сохранения состояния кластера Kubernetes все данные конфигурации кластера хранятся в распределенном хранилище ключей-значений, которое содержит только данные, связанные с состоянием кластера, но не содержит данные, сгенерированные рабочей нагрузкой клиента. Хранилище ключей-значений может быть сконфигурировано на панели управления (стековая топология) или на выделенном хосте (внешняя топология), чтобы уменьшить вероятность потери данных, отделив его от других агентов панели управления.
В стековой топологии (stacked topology) хранилища ключей-значений реплики нод панели управления с высокой доступностью обеспечивают отказоустойчивость хранилища ключей-значений. Однако это не касается хранилища ключей-значений с внешней топологией (external topology), где выделенные ноды хранилища ключей-значений должны быть отдельно реплицированы для обеспечения высокой доступности, а такая конфигурация требует дополнительного аппаратного обеспечения и, следовательно, дополнительных операционных расходов.
Нода панели управления (Control Plane Node): Компоненты.
Нода панели управления запускает следующие основные компоненты и агенты панели управления:
- Сервер API.
- Планировщик.
- Менеджер контролеров.
- Хранилище данных ключей-значений (Key-Value Data Store).
Дополнительно нода панели управления запускает следующие компоненты:
- Среда выполнения контейнера.
- Агент ноди.
- Прокси.
- Дополнительное расширение для мониторинга и ведения логов на уровне кластера.
Компоненты ноды панели управления (Control Plane Node): Сервер API.
Все административные задачи координирует kube-apiserver – центральный компонент панели управления, работающий на панели управления. Сервер API перехватывает запросы REST от пользователей, администраторов, разработчиков, операторов и внешних агентов, затем проверяет и обрабатывает их. При обработке сервер API считывает текущее состояние кластера Kubernetes из хранилища ключей-значений, а после выполнения запроса полученное состояние кластера Kubernetes сохраняется в хранилище ключей-значений для обеспечения устойчивости.
Сервер API – единственный компонент панели управления, который взаимодействует с хранилищем ключей-значений как для чтения, так и для сохранения информации о состоянии кластера Kubernetes, действуя как промежуточный интерфейс для любого другого агента панели управления, запрашивающего состояние кластера.
Серер API очень хорошо конфигурируется и настраивается. Он может масштабироваться горизонтально, но также поддерживает добавление пользовательских вторичных серверов API. Эта конфигурация преобразует основной сервер API в прокси для всех вторичных, пользовательских серверов API, маршрутизируя все входящие запросы REST на них на основе пользовательских правил.
Компоненты ноды панели управления (Control Plane Node): Планировщик.
Роль kube-планировщика (kube-scheduler) состоит в назначении новых объектов рабочей нагрузки, таких как контейнеры с инкапсулированными подами, к нодам – обычно рабочих нод. В процессе планирования решения принимаются на основе текущего состояния кластера Kubernetes и требований нового объекта рабочей нагрузки. Планировщик получает из хранилища типа ключей-значений через сервер API данные об использовании ресурсов для каждой рабочей ноды в кластере. Планировщик также получает от сервера API требования нового объекта рабочей нагрузки, являющихся частью его конфигурационных данных. Требования могут включать ограничения, установленные пользователями и операторами, например планирование работы на ноде, обозначенной парой ключ-значения disk==ssd . Планировщик также учитывает требования к качеству обслуживания (QoS), местонахождению данных, родство, антиродство, посторонние объекты, толерантность, топологию кластера и т.д. После того, как все данные о кластере доступны, алгоритм планирования фильтрует ноды с помощью предикатов, чтобы изолировать возможные ноды-кандидаты, которые затем оцениваются по приоритетам, чтобы выбрать одну ноду, удовлетворяющую всем требованиям для размещения новой рабочей нагрузки. Результат принятия решения передается обратно на сервер API, который затем делегирует развертывание рабочей нагрузки другим агентам панели управления.
Планировщик легко конфигурируется и настраивается с помощью политик планирования, плагинов и профилей. Также поддерживаются дополнительные пользовательские планировщики, тогда данные конфигурации объекта должны содержать имя пользовательского планировщика, который, как ожидается, будет принимать решение о планировании данного конкретного объекта; если такие данные не включены, вместо пользовательского планировщика будет выбран планировщик по умолчанию.
Планировщик чрезвычайно важен и сложен в многонодовом кластере Kubernetes, тогда как в однонодовом кластере Kubernetes, используемом для обучения и разработки, работа планировщика достаточно проста.
Компоненты ноды панели управления (Control Plane Node) Менеджеры контроллеров.
Менеджеры контроллеров – это компоненты ноды панели управления, запускаемые контроллерами или операторскими процессами для регулирования состояния кластера Kubernetes. Контроллеры – это непрерывно запущенные процессы, сравнивающие желаемое состояние кластера (предоставленное конфигурационными данными объектов) с его текущим состоянием (полученным из хранилища ключей-значений через сервер API). При расхождении в кластере выполняются корректирующие действия, пока его текущее состояние не будет соответствовать желаемому.
kube-контроллер-менеджер (kube-controller-manager) запускает контроллеры или операторы, ответственные за действия, когда ноды становятся недоступными, чтобы обеспечить ожидаемое количество контейнерных дел, создать конечные точки, учетные записи сервисов и токены доступа к API.
cloud-контроллер-менеджер (cloud-controller-manager) запускает контроллеры или операторы, ответственные за взаимодействие с базовой инфраструктурой облачного провайдера, когда ноды становятся недоступными, для управления балансировкой погрузки и маршрутизацией, а также предоставленными облачным сервисом службами для управления объемами хранилища.
Компоненты ноды панели управления (Control Plane Node): Хранилище типа ключ-значение.
etcd – это проект с открытым кодом под эгидой Cloud Native Computing Foundation (CNCF). etcd – это хорошо согласованное, распределенное хранилище для ключей-значений, которое используется для сохранения состояния кластера Kubernetes. Новые данные записываются в хранилище данных только путем добавления в него, данные никогда не заменяются в хранилище данных. Устаревшие данные периодически сжимаются (или измельчаются), чтобы минимизировать размер хранилища данных.
Из всех компонентов панели управления (control plane) только сервер API может взаимодействовать с хранилищем данных etcd.
Интерфейс командной строки для etcd – etcdctl – предоставляет возможности сохранения и восстановления пригодных снимков (snapshot), особенно для кластера Kubernetes с одним экземпляром etcd, что является распространенным явлением в средах разработки (Development) и обучения. Однако в среде Stage и Production очень важно реплицировать хранилища данных в режиме высокой доступности для обеспечения отказоустойчивости данных кластерной конфигурации.
Некоторые инструменты первичной загрузки кластеров Kubernetes, такие как kubeadm , по умолчанию предоставляют стеки нод панели управления etcd, где хранилище данных работает вместе с другими компонентами панели управления на той же панели управления и делит ресурсы с этими компонентами.
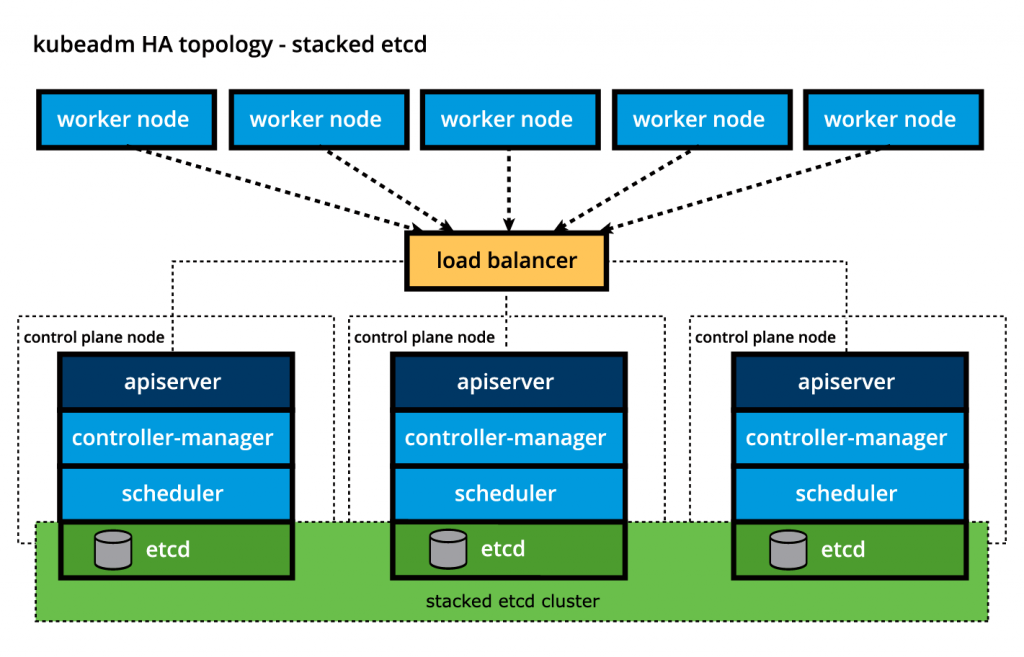
Стековая топология etcd .
Для изоляции хранилища данных от компонентов панели управления процесс первичной загрузки можно настроить на внешнюю топологию etcd, где хранилище данных размещается на выделенном отдельном хосте, таким образом уменьшая вероятность сбоя etcd.
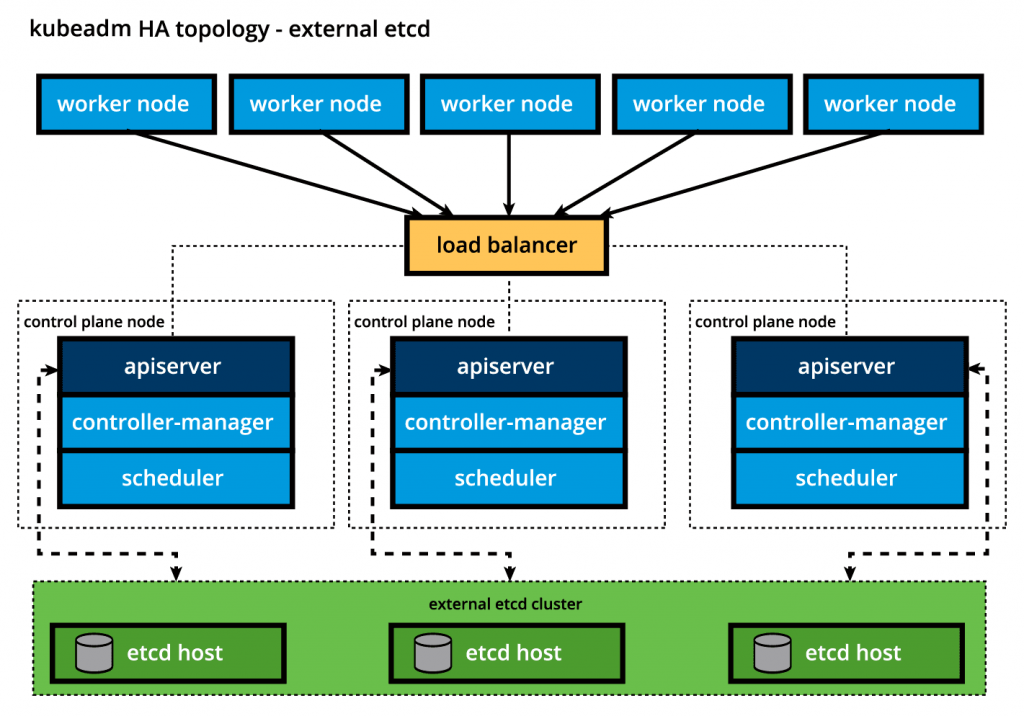
Внешняя топология etcd .
Как стековая, так и внешняя топология etcd поддерживают конфигурации высокой доступности. etcd основан на алгоритме распределенного консенсуса Raft (Raft Consensus Algorithm), который позволяет набору машин работать как слаженной группе, что может пережить сбои в работе некоторых ее членов. В любой момент одна из нод группы будет лидером, а остальные последователями. etcd отлично справляется с выбором лидера и может выдержать отказ ноды, включая отказ ноды-лидера. Лидером может быть любая нода.
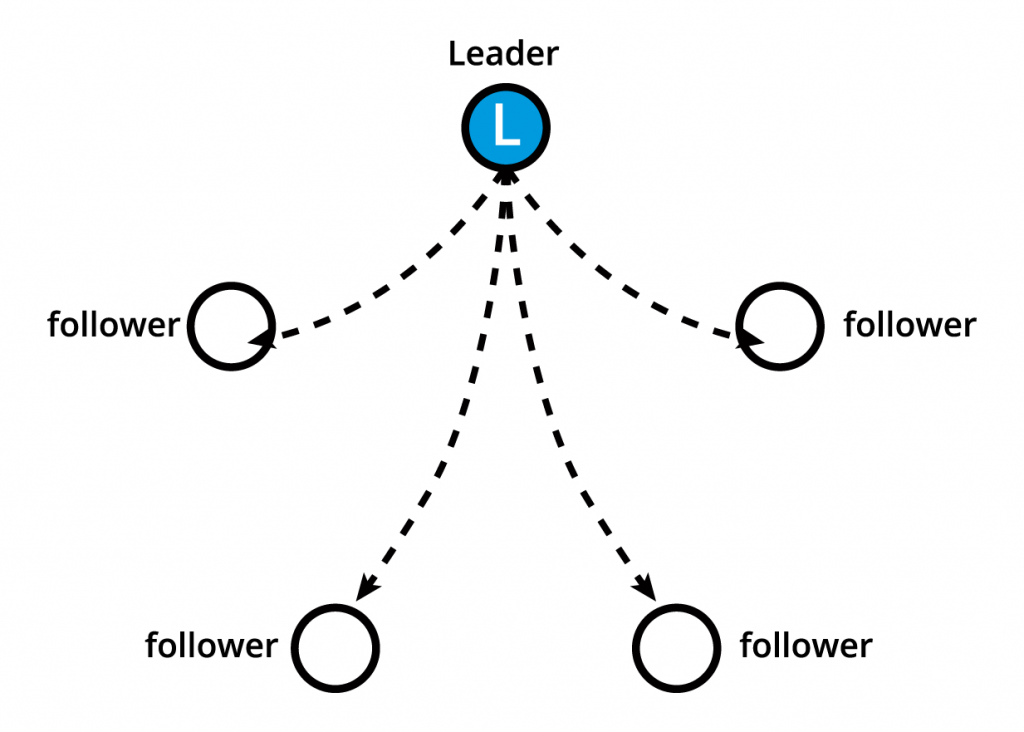
Лидеры и последователи .
etcd написано на языке программирования Go. В Kubernetes кроме хранения состояния кластера, etcd также используется для хранения деталей конфигурации, таких как подсети, ConfigMaps, Secrets и т.д.
Рабочая нода: Обзор .
Рабочая нода (worker node) обеспечивает рабочую среду для клиентских приложений. Эти приложения – микросервисы, работающие как контейнеры приложений. В Kubernetes контейнеры приложений инкапсулированы в подах (pods), которыми управляют агенты панели управления кластером, работающие на панели управления (control plane node). Поды (pods) планируются на рабочих нодах, где им предоставляются необходимые вычислительные ресурсы, память и хранилище для запуска, а также сеть для общения друг с другом и внешним миром. Под (pod) – это самая маленькая рабочая единица в Kubernetes, которую можно запланировать. Это логическая коллекция из одного или нескольких запланированных вместе контейнеров, и эту коллекцию можно запускать, останавливать или перепланировать как рабочую единицу.
Кроме того, в кластере Kubernetes, рассчитанном на многие рабочие ноды, сетевой трафик между пользователями и контейнерными приложениями, развернутыми в подах (pods), обрабатывается непосредственно рабочими нодами, а не маршрутизируется через ноду панели управления (control plane node).
Рабочая нода (Worker Node): Компоненты.
В рабочей ноде (worker node) содержатся следующие компоненты:
- Среда выполнения контейнера
- Агент ноди — kubelet
- Прокси — kube-proxy
- Расширение для DNS, пользовательский интерфейс дешборда, расширение для мониторинга и логирования на уровне кластера.
Компоненты рабочей ноды (Worker Node Components): Среда выполнения контейнера.
Хотя Kubernetes описывается как механизм оркестрирования контейнеров, ему не хватает возможности непосредственно работать с контейнерами и запускать их. Для управления жизненным циклом контейнера Kubernetes требуется среда выполнения контейнера на ноде (node), где планируется запуск пода (pod) и его контейнеров. Среда выполнения необходима на всех нодах кластера Kubernetes, как на панели управления (control plane), так и на рабочих (worker nodes). Kubernetes поддерживает несколько сред выполнения контейнеров:
- CRI-O
Легкая среда выполнения контейнеров для Kubernetes, поддерживающая реестры образов quay.io и Docker Hub . - containerd
Простая, надежная и портативная среда выполнения контейнеров. - Docker Engine
Популярная и сложная контейнерная платформа, использующая containerd как среду выполнения контейнеров. - Mirantis Container Runtime
Ранее известен как Docker Enterprise Edition .
Компоненты рабочей ноды (Worker Node Components): Агент ноды – kubelet.
kubelet – это агент, запускаемый на каждой ноде (node), как на панели управления (control plane), так и на рабочих (worker), и взаимодействует с панелью управления (control plane). Он получает определение пода (Pod), в первую очередь, от сервера API, и взаимодействует со средой выполнения контейнеров на ноде (node) для запуска контейнеров, связанных с подом (Pod). Он также отслеживает состояние и ресурсы запущенных контейнеров дел (Pods).
kubelet подключается к среде исполнения контейнеров через интерфейс на основе плагинов – интерфейс среды исполнения контейнеров (Container Runtime Interface CRI). CRI состоит из буферов протокола, gRPC API, библиотек и дополнительных спецификаций и инструментов. Для подключения к взаимозаменяемым средам выполнения контейнеров kubelet использует CRI shim – приложение, которое обеспечивает четкий уровень абстракции между kubelet и средой исполнения контейнера.
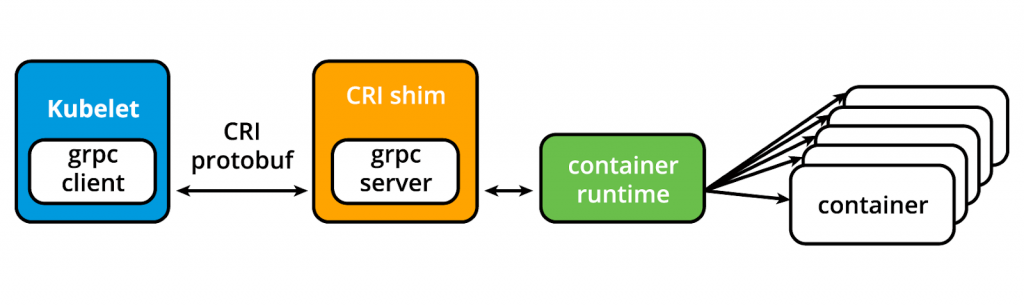
Интерфейс среды выполнения контейнера
(С сайта blog.kubernetes.io )
Как показано выше, kubelet, действующий в качестве клиента grpc, подключается к оболочке CRI, действующей как сервер grpc, для выполнения операций с контейнерами и образами. CRI реализует два сервиса: ImageService и RuntimeService . ImageService отвечает за все операции, связанные с образом, в то время как RuntimeService отвечает за поды (Pods) и операции, связанные с контейнерами.
Компоненты рабочей ноды (Worker Node Components): kubelet – оболочки (shims) CRI.
Первоначально kubelet-агент поддерживал лишь несколько сред выполнения контейнеров, сначала Docker Engine, а затем rkt, благодаря уникальной модели интерфейса, интегрированной непосредственно в исходный код kubelet. Однако такой подход должен когда-то выйти на новый уровень, хотя для Docker он был очень полезен. Со временем Kubernetes начал переходить к стандартизированному подходу к интеграции среды выполнения контейнеров, введя CRI. Kubernetes принял обособленный и гибкий метод интеграции с разными средами выполнения контейнеров без необходимости перекомпиляции исходного кода. Любая среда выполнения контейнеров с CRI может использоваться Kubernetes для управления контейнерами.
Оболочки (Shims) – это реализация интерфейса среды выполнения контейнера (CRI), интерфейсы или адаптеры, специфичные для каждой среды выполнения контейнеров, поддерживаемых Kubernetes. Ниже приведено несколько примеров оболочек CRI:
кри-контейнер
cri-containerd позволяет непосредственно создавать контейнеры и управлять ими с помощью containerd по запросу kubelet:
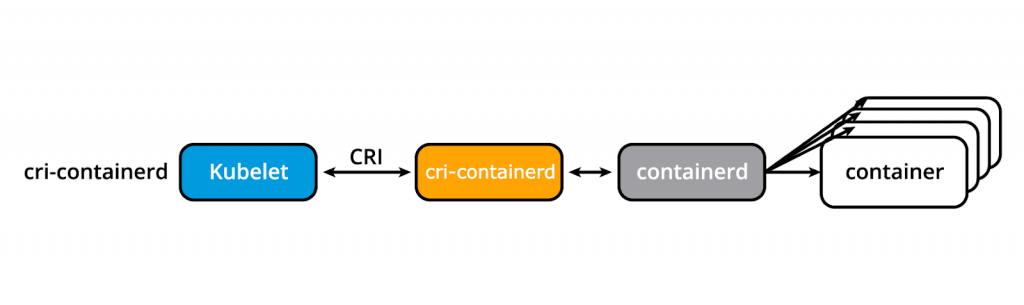
cri-containerd
(З сайта blog.kubernetes.io)
ПЛАКАТЬ ЭТО
CRI-O позволяет использовать с Kubernetes любую среду выполнения, совместимую с Open Container Initiative (OCI), например, runC:
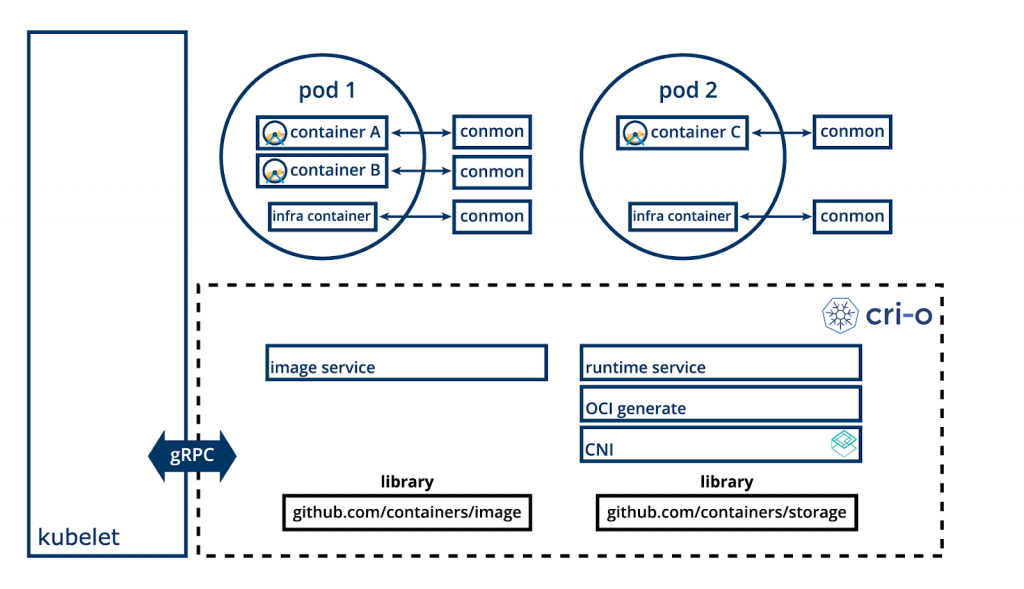
CRI-O
(З сайта cri-o.io)
докершим та кри-докерд
До версии Kubernetes v1.24 dockershim позволял создавать контейнеры и управлять ими путём вызова Docker Engine и его внутренней среды выполнения containerd. Из-за популярности Docker Engine, эта оболочка была интерфейсом по умолчанию в kubelet. Однако, начиная с версии Kubernetes v1.24, dockershim больше не поддерживается проектом Kubernetes, его специфический код изъят из исходного кода kubelet, таким образом, он больше не будет поддерживаться агентом ноды kubelet в Kubernetes. В результате, Docker, Inc. и Mirantis договорились о внедрении и поддержке адаптера на замену cri-dockerd , который гарантирует, что Docker Engine и в дальнейшем будет оставаться вариантом среды выполнения контейнеров для Kubernetes, в дополнение к Mirantis Container Runtime (MCR). Появление cri-dockerd также гарантирует, что и Docker Engine, и MCR соблюдают тот же стандартный метод интеграции, что и CRI-совместимые среды выполнения.

dockershim
(З сайта blog.kubernetes.io)
Более подробную информацию о процессе удаления dockershim можно найти на странице Обновление: Удаление Dockershim FAQ .
Компоненты рабочей ноды (Worker Node Components): Прокси – kube-proxy.
kube-proxy – это сетевой агент, работающий на каждой ноде (node), как на панели управления (control plane), так и на рабочих (workers), ответственный за динамическое обновление и поддержку всех сетевых правил на ноде. Он абстрагирует детали сетевого взаимодействия подов (Pod) и перенаправляет запросы на подключение к контейнерам в поды (Pod).
kube-proxy отвечает за переадресацию потоков TCP, UDP и SCTP или случайную переадресацию через бэкенд набора событий приложения, а также реализует правила переадресации, определенные пользователями с помощью объектов службы API.
Компоненты рабочей ноды (Worker Node Components): Расширение.
Расширение – это особенности и функции кластера, которые еще не доступны в Kubernetes, поэтому реализуются с помощью посторонних и сервисов.
- DNS
Кластерный DNS – это DNS-сервер, необходимый для назначения DNS-записей объектам и ресурсам Kubernetes. - Дешборд (Dashboard)
Универсальный пользовательский вебинтерфейс для управления кластером. - Мониторинг (Monitoring)
Собирает метрики контейнеров на уровне кластера и хранит их в центральном хранилище данных. - Логирование
Собирает журналы контейнеров на уровне кластера и хранит их в центральном хранилище журналов для анализа.
Сетевые вызовы.
Распределенные приложения на основе микросервисов полагаются на сеть, чтобы имитировать тесную связь, которая когда-то была доступна в эпоху монолитов. Вообще сетевые технологии не самые простые для понимания и реализации. Kubernetes не исключение – как оркестратор контейнерных микросервисов он должен решить несколько отдельных сетевых проблем:
- Коммуникация между контейнерами внутри подов (Pods)
- Коммуникация между подами (Pod-to-Pod) на одной и в пределах нод кластера (cluster nodes).
- Коммуникация дел с сервисами (Pod-to-Service) в пределах одного пространства имен и между пространствами имен кластера.
- Коммуникация внешнего мира с сервисом (External-to-Service) для доступа клиентов к приложениям в кластере.
Все эти сетевые вызовы необходимо решить перед развертыванием кластера Kubernetes.
Коммуникация между контейнерами внутри дел.
Используя функции виртуализации ядра основной операционной системы, среда выполнения контейнера создает изолированное сетевое пространство для каждого запускаемого контейнера. В Linux это изолированное сетевое пространство называется сетевым пространством имен (network namespace). Его можно использовать совместно с контейнерами или операционной системой хоста.
Когда запускается группа контейнеров, определенная как под, специальный инфраструктурный контейнер Pause (Pause container) инициализируется посредством среды выполнения контейнеров с целью создания сетевого пространства имен для пода. Все дополнительные контейнеры, созданные по запросам пользователей, запускаемых внутри пода, разделяют сетевое пространство имен контейнера Pause, чтобы все они могли общаться друг с другом через localhost.
Коммуникация между подами через ноды (Pod-to-Pod Communication).
В кластере Kubernetes поды, группы контейнеров, планируются на нодах почти непредсказуемым образом. Независимо от хост-ноды, пода должны иметь возможность взаимодействовать со всеми другими подами в кластере, и все это без применения трансляции сетевых адресов (Network Address Translation, NAT). Это фундаментальное требование любой сетевой реализации в Kubernetes.
Сетевая модель Kubernetes должна уменьшить сложность, и она рассматривает поды как виртуальные машины в сети, где каждая виртуальная машина оборудована сетевым интерфейсом – таким образом, каждый «под» получает уникальный IP-адрес. Эта модель называется IP-per-Pod и обеспечивает коммуникацию между подами (Pod-to-Pod), так же, как виртуальные машины могут общаться между собой в одной сети.
Не забывайте о контейнерах. Они разделяют сетевое пространство имен пода и должны координировать назначение портов внутри пода так же, как программы на виртуальной машине, и при этом могут общаться друг с другом на localhost – внутри пода. Тем не менее, контейнеры интегрированы в общую сетевую модель Kubernetes с помощью сетевого интерфейса контейнеров (Container Network Interface, CNI), поддерживаемого плагинами CNI . CNI – это набор спецификаций и библиотек, позволяющих плагинам настраивать сеть для контейнеров. Хотя существует несколько основных плагинов , большинство плагинов CNI – это сторонние программно-конфигурированные сетевые решения (SDN), реализующие сетевую модель Kubernetes. В дополнение к основным требованиям сетевой модели некоторые сетевые решения предлагают поддержку сетевых политик. Flannel , Weave , Calico – это лишь некоторые из вариантов SDN, доступные для кластеров Kubernetes.
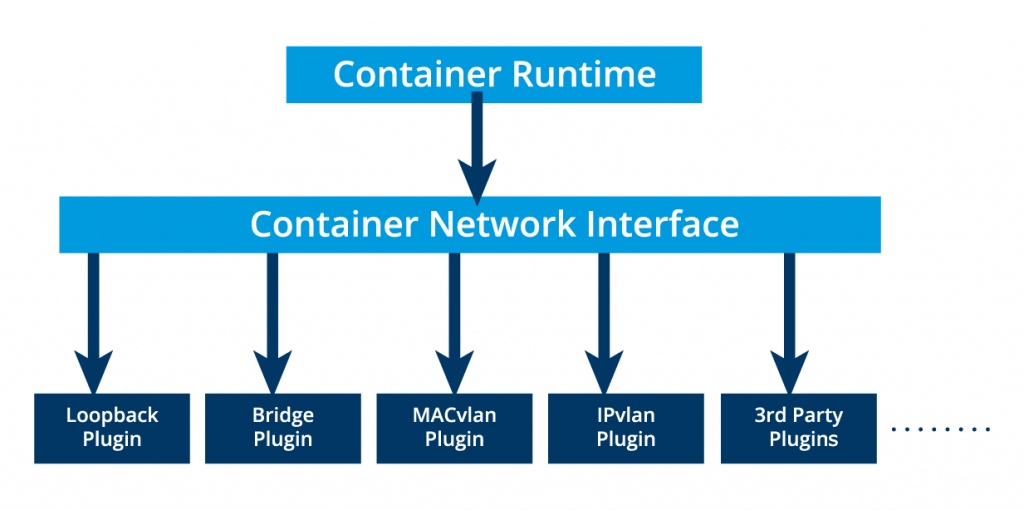
Основные плагины контейнерного сетевого интерфейса (CNI)
Среда выполнения контейнера выгружает назначение IP-адреса в CNI, который подключается к базовому настроенному плагину, такому как Bridge или MACvlan, чтобы получить IP-адрес. После получения IP-адреса от соответствующего плагина, CNI пересылает его обратно в запрашиваемую среду выполнения контейнера.
Более подробная информация доступна в документации Kubernetes .
Коммуникация событий с внешним миром (Pod-to-External World).
Успешно развернутому контейнерному приложению, работающему в подах внутри кластера Kubernetes, может потребоваться доступ из внешнего мира. Kubernetes обеспечивает внешний доступ с помощью сервисов (Services) , сложных инкапсуляций определений и правил сетевой маршрутизации, хранящихся в iptables на нодах кластера и реализуемых агентами kube-proxy . Открывая сервисы для внешнего мира с помощью kube-proxy , приложения становятся доступными извне кластера через виртуальный IP-адрес и выделенный номер порта.
Проверка знаний 4.1.
Кластер Kubernetes может содержать несколько нод панели управления (control plane node) для обеспечения высокой доступности панели управления. Истинно ли ошибочно это утверждение?
Ответ: Правдивое .
Проверка знаний 4.2
Что из нижеприведенного относится к компонентам ноды панели управления (control plane node)?
Ответ:
Планировщик.
См. также
Менеджер контролеров.
См. также
Сервер API.
Проверка знаний 4.3
Для выполнения какой-либо административной задачи администратор взаимодействует с:
Ответ:
kubelet.
См. также
Сервером API
Учебные цели (Итог).
Теперь вы можете:
- Будете обсуждать архитектуру Kubernetes.
- Объяснять различные компоненты панели управления и рабочих нод.
- Обсуждать управление состоянием кластера с помощью etcd.
- Рассматривать требования Kubernetes к настройке сети.
Раздел 5. Установка Kubernetes .