«SpaCy» — это программная библиотека с открытым исходным кодом для расширенной обработки естественного языка, написанная на языках программирования Python и Cython.
Читала в книгигe «Обработка_естественного_языка_Python_и_spaCy_на_практике_2021_Васильев.pdf» как сделать бот. Узнал про библиотеку «SpaCy«.
Нашел статью «Обработка и анализ естественного языка с помощью Python-библиотеки spaCy«
https://habr.com/ru/companies/otus/articles/755584/
и пробую разобраться с этой библиотекой и как ее я могу применять для изучения Немецкого и Английского языков
и проекта «pr. ПО помогает общаться и изучать язык«
ВНИМАНИЕ !!!
Если версия на компьютере несколько то нужно выяснить в какую версию будут устанавливаться. библиотеки.
в программе
import sys
print(sys.version)
в cbm
py —version
python —version
python3 —version
python3.12 —version
Обновить версию pip
py -m pip install -U pip
как установить библиотеку «SpaCy» ?
Чтобы установить библиотеку SpaCy, выполните следующие шаги:
Установите зависимости: эти две библиотеки нужны для работы библиотеки «SpaCy» !
pip install numpy cython
или апгрейд если «SpaCy» уже установлена.
py -m pip install -U numpy cython
py -m pip install —upgrade numpy cython
Установите SpaCy:
pip install spacy
или апгрейд если «SpaCy» уже установлена.
py -m pip install -U spacy
py -m pip install --upgrade spacy
Загрузите языковую модель (например, для русского языка):
Русского
Для маленькой модели:
python -m spacy download ru_core_news_sm
Для средней модели:
python -m spacy download ru_core_news_md
Для большой модели:
python -m spacy download ru_core_news_lg
Английский:
Маленькая модель:
python -m spacy download en_core_web_sm
Средняя модель:
python -m spacy download en_core_web_md
Большая модель:
python -m spacy download en_core_web_lg
Немецкий:
Маленькая модель:
python -m spacy download de_core_news_sm
Средняя модель:
python -m spacy download de_core_news_md
Большая модель:
python -m spacy download de_core_news_lg
Украинский:
Маленькая модель:
python3 -m spacy download uk_core_news_sm
Средняя модель:
python3 -m spacy download uk_core_news_md
Большая модель:
python3 -m spacy download uk_core_news_lg
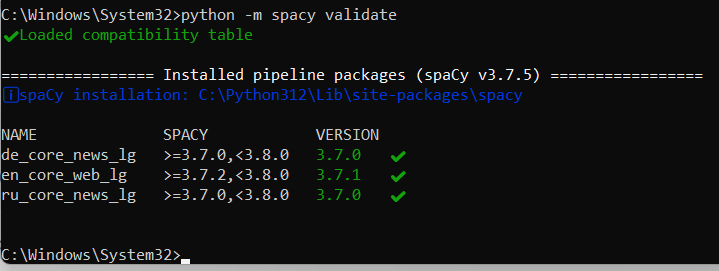
Команда
python -m spacy validateиспользуется для проверки совместимости всех установленных моделей и пакетов spaCy с текущей версией spaCy, установленной в вашей среде
Это особенно полезно после обновления spaCy, чтобы убедиться, что все модели и пакеты работают корректно.
Маленькая модель (sm):
Размер: около 14 МБ
Средняя модель (md):
Размер: около 39 МБ
Большая модель (lg):
Размер: около 489 МБ
Приведение слов к их базовой форме
Лемматизация — это процесс приведения слова к его базовой форме (лемме) путем удаления окончаний и суффиксов. Это помогает унифицировать различные формы слова и улучшить точность анализа.
Пример:
#de_core_news_sm
b = "de_core_news_sm"
import spacy
nlp = spacy.load(b)
text = 'Der Plan der Allianz zur Übernahme des singapurischen Versicherers Income Insurance für 1,5 Milliarden Euro stößt in dem südostasiatischen Finanzzentrum auf massive Kritik. Das berichtet das "Handelsblatt".'
doc = nlp(text)
for token in doc:
if (token.text != token.lemma_):
print(f"{token.text} <> {token.lemma_};")
else:
print(f"= {token.text}")
Результат:
Der <> der;
= Plan
= der
= Allianz
zur <> zu;
= Übernahme
des <> der;
singapurischen <> singapurisch;
Versicherers <> Versicherer;
Income <> Incom;
= Insurance
= für
= 1,5
Milliarden <> Milliarde;
= Euro
stößt <> stoßen;
= in
dem <> der;
südostasiatischen <> südostasiatisch;
= Finanzzentrum
= auf
massive <> massiv;
= Kritik
. <> --;
Das <> der;
berichtet <> berichten;
das <> der;
" <> --;
= Handelsblatt
" <> --;
. <> --;Пример программы которая выдает полезный результат: Файл «test_v1.py»
#de_core_news_sm
b = "de_core_news_sm"
text = 'Der Plan der Allianz zur Übernahme des singapurischen Versicherers Income Insurance für 1,5 Milliarden Euro stößt in dem südostasiatischen Finanzzentrum auf massive Kritik. Das berichtet das "Handelsblatt".'
from lebery_jp import find_value_by_key__token_lemma
#------------------
import spacy
# Загружаем языковую модель
nlp = spacy.load(b)
# Входной текст
#text = "I like to read books."
# Применяем анализ
doc = nlp(text)
# Выводим слова и их части речи
for token in doc:
t = token.lemma_ if (token.lemma_ != "--") else ".,?!"
print(f"{token.text} ({"<-" + t + "; "if (token.text != t) else "= ;"}-> {find_value_by_key__token_lemma(token.pos_)})")
Файл библиотека в той же папке «lebery_jp.py»
def find_value_by_key__token_lemma(key):
"""
Функция ищет значение по ключу в заданном словаре.
:param data: словарь, в котором нужно искать
:param key: ключ, по которому нужно найти значение
:return: значение, соответствующее ключу, или None, если ключ не найден
"""
data = {
"DET": "DET: Artikel oder Determinator (артикль или определитель)",
"NOUN": "NOUN: Substantiv (существительное)",
"ADP": "ADP: Präposition (предлог)",
"ADJ": "ADJ: Adjektiv (прилагательное)",
"PROPN": "PROPN: Pronomen Substantiv (имя собственное)",
"NUM": "NUM: Zahlwort (числительное)",
"VERB": "VERB: Verb (глагол)",
"PUNCT": "PUNCT: Satzzeichen (знак препинания)",
"PRON": "PRON: Pronomen (местоимение)"
}
return data.get(key, "Не найжено: " + key)