папка «*\HTML_CSS_JS_2023\Выделение тегами отличий при сравнении 2х похожих строк»
Teg: сравнение строка, выделение различий, выделить цветом различия, найти разницу, найти различия,
http://l.cbm.ua/help/index.html — Сравнение 2х текстов (Comparison of 2 texts)
Цель подсветить части которые удалены и добавлены в тексте.
Для этого есть библиотека которая перед каждым таким символом ставит или + (символ добавлен) или — (символ удален).
Дальше каждый такой символ обрамляется своим тегом.
Дальше чтобы уменьшить размеры текст для определения стилей и не выделять каждый символ отдельно просто удаляется одинаковый тег конца и начала. Например:
Скрипт для сравнения двух строк:
s_r1 = s_r1.replace("</jV1><jV1>", "")
s_r2 = s_r2.replace("</jV2><jV2>", "")
таким образом вместо этого <jV1>a</jV1><jV1>b</jV1><jV1>c</jV1> получаем это <jV1>abc</jV1>
import difflib
cases=[('afrykanerskojęzyczny', 'afrykanerskojęzycznym'),
('afrykanerskojęzyczni', 'nieafrykanerskojęzyczni'),
('afrykanerskojęzycznym', 'afrykanerskojęzyczny'),
('nieafrykanerskojęzyczni', 'afrykanerskojęzyczni'),
('nieafrynerskojęzyczni', 'afrykanerskojzyczni'),
('abcdefg','xac')]
for a,b in cases:
print('{} => {}'.format(a,b))
for i,s in enumerate(difflib.ndiff(a, b)):
if s[0]==' ': continue
elif s[0]=='-':
print(u'Delete "{}" from position {}'.format(s[-1],i))
elif s[0]=='+':
print(u'Add "{}" to position {}'.format(s[-1],i))
print()
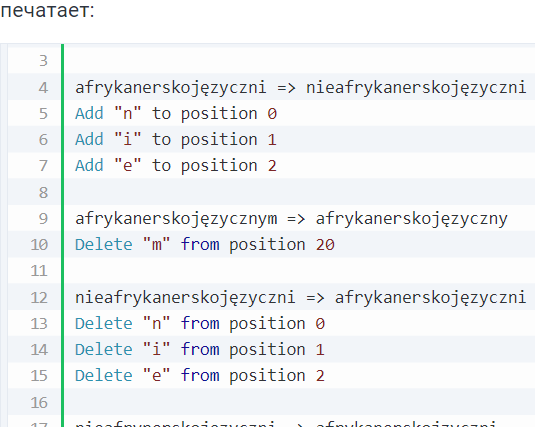
Будет напечатано:
afrykanerskojęzyczny => afrykanerskojęzycznym Add "m" to position 20 afrykanerskojęzyczni => nieafrykanerskojęzyczni Add "n" to position 0 Add "i" to position 1 Add "e" to position 2 afrykanerskojęzycznym => afrykanerskojęzyczny Delete "m" from position 20 nieafrykanerskojęzyczni => afrykanerskojęzyczni Delete "n" from position 0 Delete "i" from position 1 Delete "e" from position 2 nieafrynerskojęzyczni => afrykanerskojzyczni Delete "n" from position 0 Delete "i" from position 1 Delete "e" from position 2 Add "k" to position 7 Add "a" to position 8 Delete "ę" from position 16 abcdefg => xac Add "x" to position 0 Delete "b" from position 2 Delete "d" from position 4 Delete "e" from position 5 Delete "f" from position 6 Delete "g" from position 7
Скрипт (программа) для сравнения 2х строк и выделения тегами тех букв которые удалены или добавлены.
Чтобы получилось так:

Скрипт (программа) на Python-е для подготовки строк с разделителями измененных букв тегами.
import difflib
cases=[]
mas_1 = [()]
cases=[
('befehlen', 'befiehlt'),
('backen', 'bäckt'),
('backen', 'backt'),
('backen', 'buk'),
('backen', 'backte'),
('backen', 'hat gebacken')
]
for a, b in cases:
print(f'{a} => {b}')
s_r1 = ""
s_r2 = ""
for i, s in enumerate(difflib.ndiff(a, b)):
if s[0] == "-":
s_r1 += "<jV1>" + s[2:] + "</jV1>"
elif s[0] == "+":
s_r2 += "<jV2>" + s[2:] + "</jV2>"
else:
s_r1 += s[2:]
s_r2 += s[2:]
#Тут можно в строках с результатами "s_r1" и "s_r2" удалить закрывающийся
# и открывающийся теги. Например "</jp1><jp1>" или чтото подобное.
#Так как иначе будет выделяться каждая буква отдельно.
s_r1 = s_r1.replace("</jV1><jV1>", "")
s_r2 = s_r2.replace("</jV2><jV2>", "")
print (f'{s_r1}, {s_r2}')
print()

Для изучения немецкого языка.
Сравнение 2х строк
befehlen => befiehlt
versicherung,sach versicherung versicherung,rück versicherung versicherung,kasko versicherung versi cherung, verschlecht erung versich erung, verste ig erung
в папке тут
***\HTML_CSS_JS_2023\Выделение тегами отличий при сравнении 2х похожих строк